HTTP缓存机制
HTTP 缓存机制
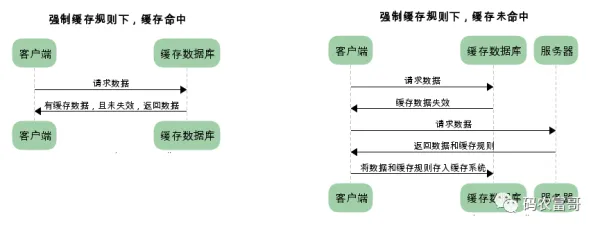
强缓存
涉及到字段:
● 请求返回 Expire 字段 http1.0 的产物,来设置过期时间,它是服务端生成,可能存在客户端和服务器端时间不一致,或者前端可以修改本地时间,导致缓存命中产生误差,目前基本都被 Cache-Control 替代了
● Cache-Control http1.1,一般使用 max-age 来设置缓存多长时间,单位秒;no-store 禁止一切缓存,no-cache 强制客户端向服务器发请求,服务器收到请求,然后判断内容是否变更,变更了就返回新内容,没有就返回 304;这个单词很容易误解,以为不缓存,其实是会被缓存的,只不过每次请求,都要服务端验证缓存。
协商缓存
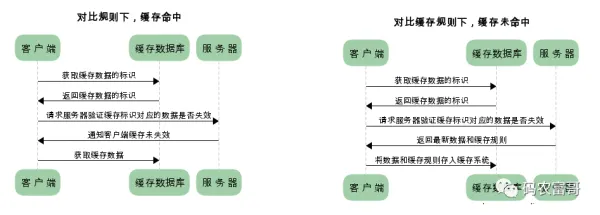
第一次请求数据:服务器会将缓存标识和数据返回给浏览器,然后将两者保存在缓存数据库中
再次发请求:浏览器会将标识发送给服务器检测,是否过期,如果没有过期,就返回 304 状态码,可以使用缓存数据,如果过期了,服务器重新响应数据。
有两对字段配合检测缓存是否过期
● Last-Modified / If-Modified-Since:服务器响应的时候会返回,访问的资源最后修改的时间 Last-Modified,下一次请求的时候,会通过 If-Modified-Since 字段带上修改的时间,服务器回去对比资源修改的时间,如果不相同就说明修改过了,返回新的响应数据,重新缓存,如果相同就可以继续使用缓存,并返回 304 状态码。
● Etag / If-None-Match(优先级高于 Last-Modified / If-Modified-Since):服务器响应的时候,会返回一个当前资源的标识(唯一的),下一次请求的时候,会通过 If-None-Match 字段带上这个标识,服务器去对比传过来的标识和当前资源的标识是否一致,如果不一致说明被修改过了,否则就可以继续使用缓存,并返回 304 状态码。
为什么存在 Last-Modified 和 Etag 一起设置的情况?
Etag 和 Last-Modified 是允许一起使用的,服务器会优先验证 Etag,在 Etag 一致的情况下,再去对比 Last-Modified,这是为了防止有一些 HTTP 服务器未将文件修改日期纳入哈希范围内。
我们知道 Etag 是根据文件内容来生成哈希值的,ETag 的值,默认是对文件的索引节点(INode),大小(Size)和最后修改时间(MTime)进行 Hash 后得到的。假如我生成 Etag 生成策略不包含修改时间,改完后的内容索引节点和大小还是一样,其实内容变了,但是由于生成策略不包含修改时间,导致生成 Etag 一样了,所以还要通过 Last-Modified 字段来判断资源修改时间。
为什么要有两种缓存呢?有了强缓存为什么还要有协商缓存?
因为强缓存有缺陷,假如通过 max-age 设置了过期时间,到了过期时间,但是其实内容并没有变更,就需要重新拉取资源,因此就有了 Last-Modified 字段,用来对比前后资源修改的时间,但是 Last-Modified 字段也有缺陷,因为它的时间是 s,如果 1s 内有资源修改了,它的修改时间是不会变的,所以还是会命中缓存的,不会重新获取资源的,最后就推出了 Etag,通过对比资源内容的来判断是否修改。
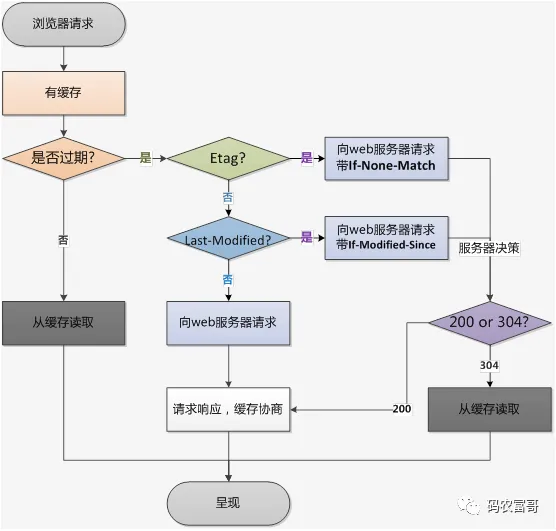
HTTP 缓存整体流程图
强缓存优先级高于协商缓存
参考文章: